Consuming Multiple OpenStack Clouds with Ease
- Monty Taylor
- https://www.openstack.org/videos/boston-2017/consuming-multiple-openstack-clouds-with-ease
- Shade - what is it?
- Task oriented lib
- Multi-Cloud
- Scalable (used on 20k servers a day in managing OpenStack CI)
- Logic design is borrowed heavily from nodepool
- lib in Python and Ansible
- https://github.com/openstack-infra/shade
- #openstack-shade on freenode
Side note: presentation was made using https://pypi.python.org/pypi/presentty
We got a walkthrough of the module, and a demo where a server was created and destroyed in 3 different clouds, located in 3 different providers (with different credentials)
Shade relies on
clouds.yaml, which is an emerging replacement for.openrcfiles, and supports multiple cloudsSee: https://git.openstack.org/cgit/openstack/os-client-config/tree/README.rst
Credentials can optionally be separated into
secure.yaml; if this is done, the two are merged for the final configYou can use
clouds.yamlto override service catalog, and describe capabilities of the cloud in the definitionShade supports two debug modes:
debugandhttp_debughttp_debugshows every http call in full detaildebugshows function calls and logging, but hides actual HTTP calls/responsesShade uses munch objects, which support both standard dictionary notations and dotted, javascript style notation
Speed Mentoring Lunch
- Women of OpenStack event, sponsored by Intel
- https://www.openstack.org/summit/boston-2017/summit-schedule/events/18680/speed-mentoring-lunch-sponsored-by-intel
I was a technical mentor for this event, which was 3 rounds of 10 minutes each, where mentees asked questions about OpenStack. I met about 10 men and women using OpenStack and we talked about a wide range of topics, including:
- How to get started as a contributor
- Merits, challenges and differences of different Cinder backends
- whether or not it is worth moving from Kilo to Ocata (yes), as well as a strategy for doing so.
Canonical - Hybrid Cloud Kubernetes
This started off a little slow, but Mark made some good points. He emphasized:
- Decoupling workload from Infrastructure
- Developers should not have to care how they get Infrastructure
- Everyday Operations and costs should be manageable enough to just fade to background
- Staying close to upstream is crucial
- Can you upgrade? Diverging makes this harder
- Have you forked beyond all recognition (note the similarity to FUBAR)
- Pull operations away from architecture; while it's important to understand operations when making architecture decisions, operators should be able to do a most things without a deep understanding of architecture (I disagree with this)
We then got an overview of OpenStack on Kubernetes, and a comparison of objects on demand (VMs) with processes on demand (containers). He also talked about the similarities of LBaaS with the Kubernetes model. He also talked about LXD and called it "containers for old people", asserting that it is a fat container that acts more like a VM.
Next was a live demo of deploying OpenStack on Kubernetes via MAAS and Juju. He deployed version 1.5.x of the following Kubernetes components using MAAS/Juju:
- easyrsa
- flannel
- kubernetes load_balancer
- kubernetes master
- kubernetes worker
He demonstrated upgrading the Kubernetes installation to 1.6.x using set channel=n.n. in Juju. While upgrading, he also did a topology expansion, and Juju did rolling upgrades of Kubernetes while adding nodes, without interrupting services.
When One Cloud is Not Enough: An Overview of Sites, Regions, Edges, Distributed Clouds, and More

This presentation came out of the common interest of several working groups supporting large OpenStack clouds. The talk was focused on the merits of different approaches depending on the use case. Some of the tools for scaling a large OpenStack cloud include:
- Cells (v1 for now, because v2 only supports single Cell until Pike)
- Availability Zones
- Host Aggregates
- Other native OpenStack tools
- External tools (Kubernetes, for example)
The WAN/Wide model:
- Control plane in a single DC
- Compute is deployed at all locations and uses control plane in main DC
- Lots of issues
- No HA, main DC is a single point of failure
- Latency
- Scaling is tough, because single control plane means a bloated DB and messaging layer
OpenStack Nova Cells (v1) model:
- Strategy for scaling Nova
- Has DB and messaging in each cell
novaDB, notnova_apiDBnova_apiDB is global,novaDB is per cell- Multiple failure domains
- Only solves scale issues and HA for nova
- New, but being developed heavily (Cells v2)
- Used by large scale clouds like CERN and NeCTAR
OpenStack Regions:
- Multiple complete OpenStack installations per region (except Keystone)
- Usually per DC
- Shared Keystone
- Only AuthN/AuthZ are shared; quotas, ssh-keys, etc are not shared
- Single Keystone == SPOF
Primary Keystone with Async Replication to other Regions model:
- Recommended approach of OPNFV installs
- Keystone shared across regions via Galera
- Shared auth
- Looks like a public cloud, walks like a public cloud, feels like a public cloud
- Operationally complex
- Limited to low number of clouds/regions
- Upgrades are harder, because of global coordination
Multi Cloud model:
- No shared anything
- Independent Authentication
- Managed by abstraction layer above (tooling like shade, cloudforms, or something written in house)
OpenStack Federation model:
- Independent clouds
- Uses trust model (think AD trusts)
- K2K (keystone to keystone)
- Shared auth, but no shared keystone
- Complex
- Manage mappings between clouds
- Often requires role and resources cleanup
OPNFV Multisite model:
- Tri-Circle
- I feel this really only makes sense in the OPNFV / Carrier space
- Shared Keystone (Async)
Securing Microservice Interactions in OpenStack and Kubernetes
This talk discussed the benefits of a microservice architecture, as well as new challenges like:
- Multi Cloud
- Sprawling attack surface
- Tying into data plane
- Major IT trends putting data at risk
- cloud native microservices migrating to intra-cloud/multi-cloud (whoa jargons)
- global identities are hard, so the tendency is to take shortcuts
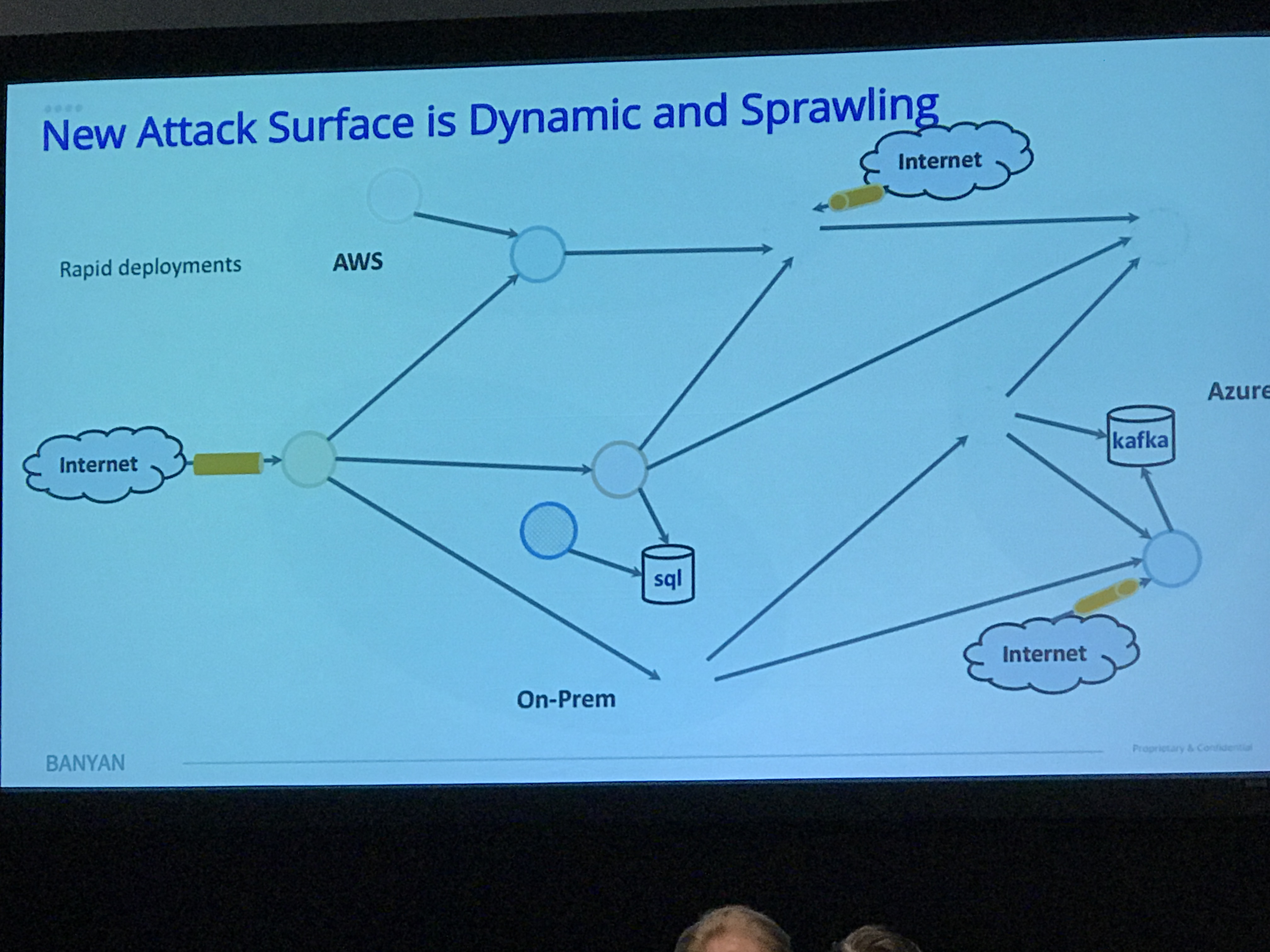
Requirements for a solution to these issues must be:
- Dynamic
- Distributed
- Independent of Infrastructure
- Easy to use (or people won't)
- Self verifying
OpenStack tools for this:
NetSec
RBAC
Virtual Routing
FWaaS
Security Groups
AppSec
Barbician
LBaaS : L7 plugins
Banyan asserts that these are all primitives and are not complete.
Kubernetes tools:
NetSec
Network policy
Segmentation with CNI tools like Contrail or Calico
AppSec
Secrets management
There are discussions on service based policies, but not implemented yet
Side by side tools and options:
- Magnum or Kubernetes on OpenStack
- Global choke/enforcement point
- Kuryr
- Bridge K8s to Neutron
- Kuryr CNI plugin in K8s
- Same model in both, adds Neutron features to K8s
What Banyan is proposing:
- Merge of NetSec/AppSec
- Cryptovisor they make runs everywhere
- Central policy
- Applied to each cell/VM
- Sits between apps and network
- Define least privilege, mutual TLS encryption for transit between every point
- Transparent to applications
- Global identities for mutual TLS
- Policy is RBAC and dynamic
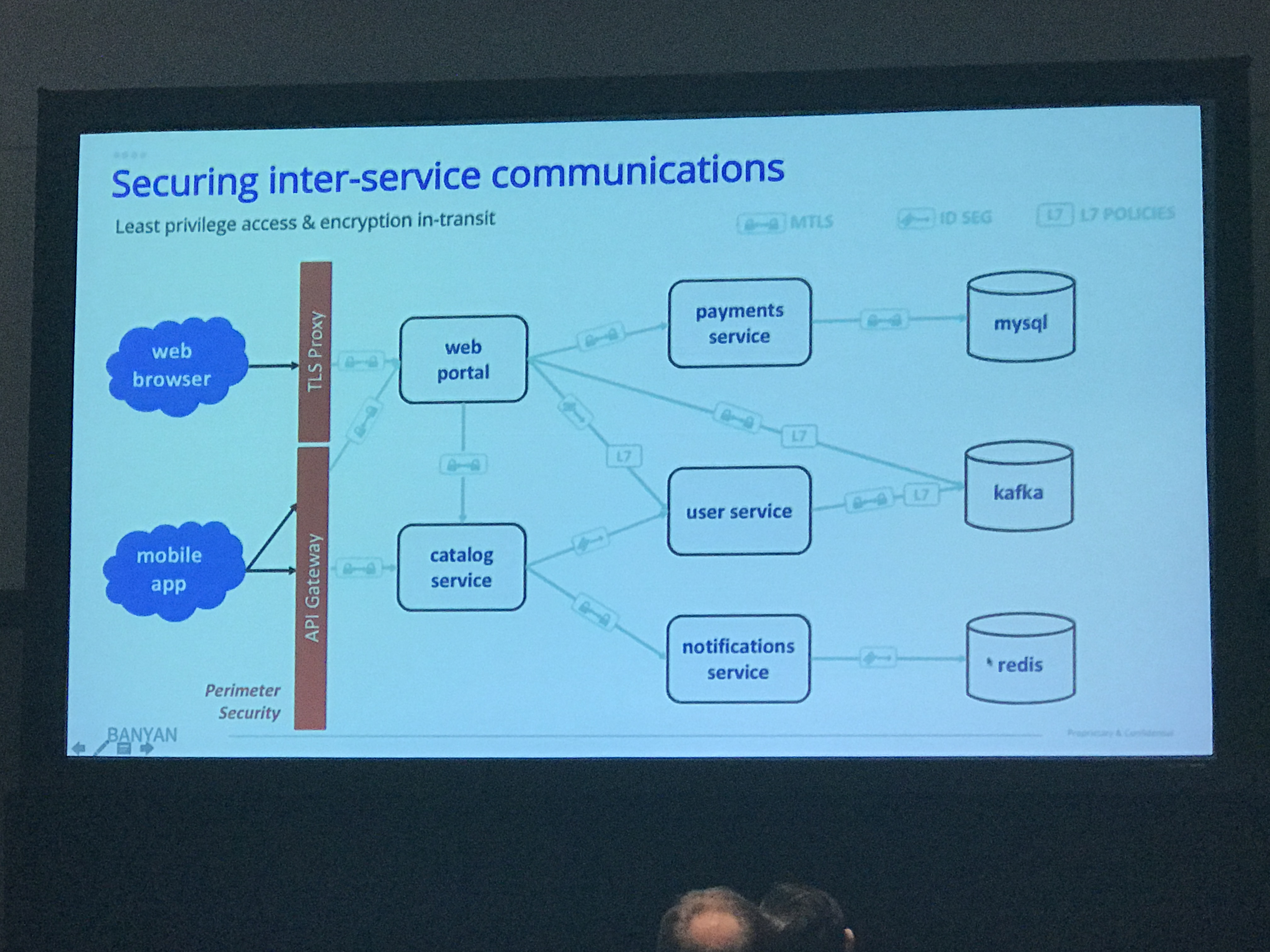
This was followed by a demo with an app running over this architecture.
Nova Cells v2 Forum
As CellsV2 is required in Ocata and multicell-capable in Pike, a coordination session between the developers and operators would be beneficial. Ideally we would come out of the session with a few operators that are interested in helping forge ahead with CellsV2 to identify pain points and integration issues early. All participants can expect to come away with a better understanding of CellsV2 in general, as well as a better understanding of how it affects all users of Nova going forward.
Related docs are here: https://wiki.openstack.org/wiki/Nova-Cells-v2
Etherpad from this session is here: https://etherpad.openstack.org/p/BOS-forum-cellsv2-developer-community-coordination
Topics discussed:
- Get everyone off Cells V1
- Ocata Cells v2
- Only supports single cell (and cell 0 graveyard), more cells will break everything
- Pike Cells v2
- Multi cells support
- devstack against multi cell is almost working, with tempest support too
- importance of avoiding upcalls (calling APIs in parent cell) - main source are:
- scheduler affinity
- reschedules - these will be 95% eliminated as placement API gains traction
- Placement API is main plan for avoiding upcalls
- Reschedules should be handled by Heat, Nova is not an orchestration tool
- Most retries fail
- Suggestion to have nova-compute nodes down themselves after threshold of failed
nova bootattempts (NoValidHost case) - CERN never retries and that makes dev community happy
- Largest proponent of retries was an Operator with a lot of bare metal
- Compromise was to retry within Cells, but not in top level Cell
- Dev community asked for Operators to test multi cells, and Operators volunteered
- Quotas getting out of sync with reservations
- A lot of people cron cleanup to prevent bloat in DB
- Suggested that quotas be changed to use boot time numbers instead of reservations, with the understood risk that people could potentially exceed quotas in this model. Could be abused by malicious users
- Cells v1 needs a migration path
- CERN
- NeCTAR
Building and Operating an OpenStack Cloud with a Small Team
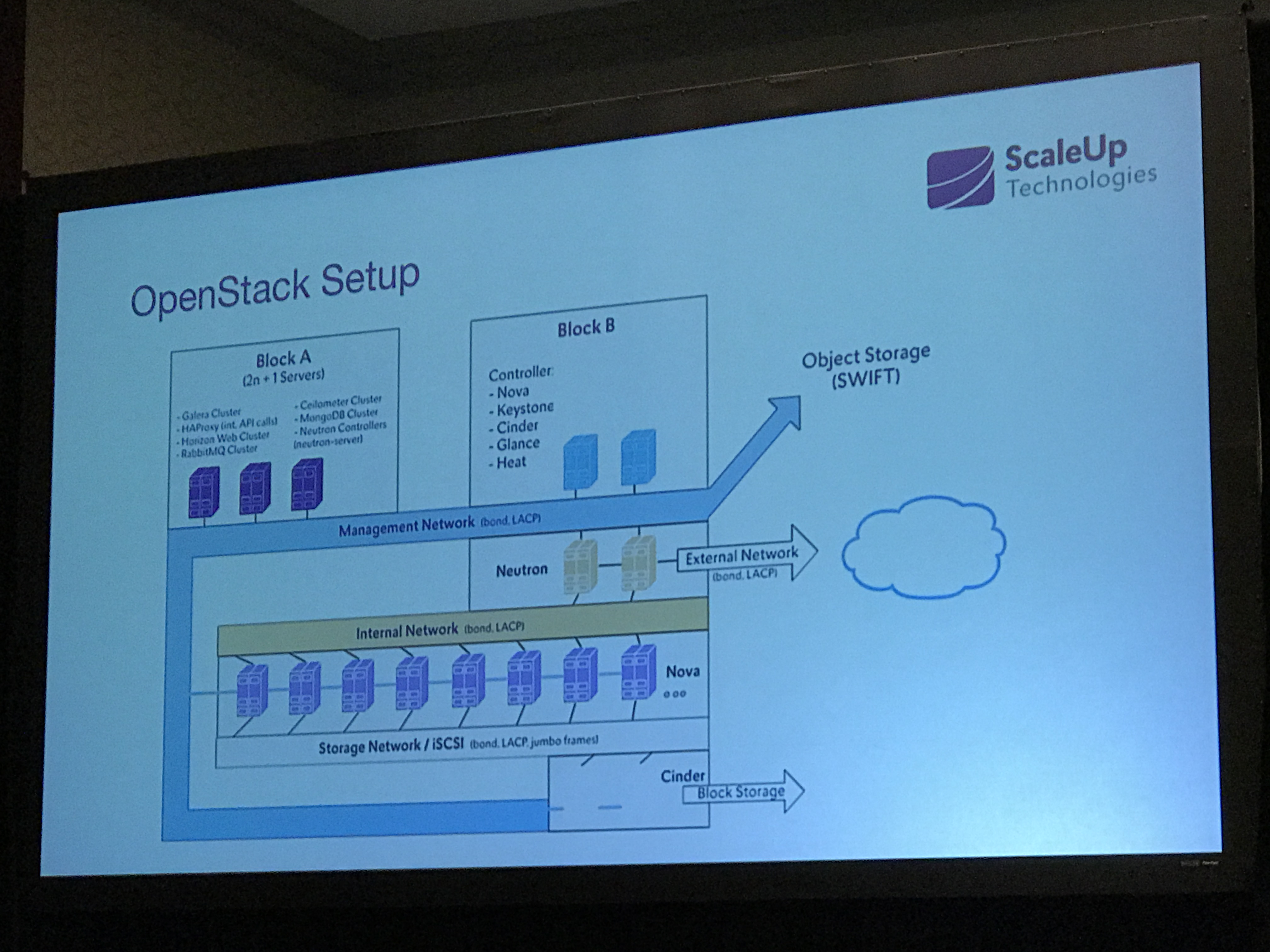
ScaleUp is a small group, based in Germany. Their OpenStack team was two people until late 2016, when a third person joined. The have four datacenters in Germany, two in Hamburg, and two in Berlin. They run vanilla OpenStack on Ubuntu.
They talked about focusing on HA from the beginning, due to the small staff.
Their infra included (at the start):
- 40 compute nodes
- 2 controllers
- 20-150 VMs (mostly their own infrastructure)
Next steps:
- Replace old gear
- Increase network speeds
- Migrate Cinder to Ceph
- Standardize HW
- Minimum of 3 controllers
How does this work with a small team?
- Abstract workloads into categories
- HW/Infra problems don't bubble up to OpenStack team (well defined escalation path)
- Teams focus on a category (specialization)
- Farm inexperienced staff, increase their skills
- Not everything OpenStack is an OpenStack problem (escalation path again)
- They monitor with Check_MK
- For DB problems, engage DB team early, instead of trying to have OpenStack team handle it
- They ran into problems with Galera behind HA Proxy
- They resolved problems with connection affinity for back ends, but did not split reads and writes, which is a common approach
- Pacemaker/Corosync/Haproxy for HA
- ELK for a single pane of glass
- Centralized logging and alerting is essential
What do you do when all hell breaks loose?
- Runbooks
- Scripting and automated remediation whenever possible
- Restarting the message queue often helps
- Learn from problems and outages, and communicate these widely, without blame
- In an emergency, you can use libvirt directly, manually to temporarily restore an app while figuring out OpenStack problems
What about upgrades?
- Juno to Kilo - OK
- Kilo to Liberty - OK
- Liberty to Newton - they had problems and rolled back
- requires OS upgrade
- python lib incompatibilities were a challenge
- Test env gets promoted to production
- Migrate VMs by compute node, as each node is empty, remove from old env and join to new
What about block storage?
- Potentially migrating to Ceph
- Might just attach existing Cinder backend
For monitoring, they use mongo DB, hosted in OpenStack, and they plan to move to Ceilometer and Gnocchi
Their current infra looks like this:
They suggested doing things the hard way, rather than using installers or automating yourself, because you learn more, and that is valuable. In closing, they wanted to tell small companies "you can do this".
