Oslo Developer/Operator Feedback
- ChangBo Guo
- https://www.openstack.org/summit/boston-2017/summit-schedule/events/18762/oslo-developeroperator-feedback
- https://etherpad.openstack.org/p/BOS-Oslo-brainstorming
This was a brainstorming dev/user session for the oslo middleware that unifies communications between OpenStack components. Topics included testing against PyPy, configs in etc.d (or potentially consul), messaging and potential changes to rootwrap and privsep.
A suggestion to better support alternatives to RabbitMQ for AMQP messaging in this forum bore fruit in the next oslo forum and are detailed in this etherpad: https://etherpad.openstack.org/p/BOS_Forum_Oslo.Messaging_driver_recommendations
The oslo impact most visible to Operators was agreed to be:
- messaging
- config
- logging
- policy
I learned a lot in this session. It's another one that was not recorded, but was very engaging and informative.
CERN: Containers on the Cloud
- Adrian Otto (Magnum PTL)
- Ricardo Rocha (CERN)
- https://www.openstack.org/videos/boston-2017/cern-containers-on-the-cloud
This started off pretty light, with stuff like "what is CERN". We got some cool slides with pics of the LHC and the 'stats slide':

Next we got an overview of Magnum. Details included:
- Uses Keystone credentials
- Multi-tenant control and data planes
- Choice of COE (Cluster Orchestration Engine):
- Kubernetes
- DC/OS
- Docker Swarm
- Mesos
- Modular, so any COE can be added
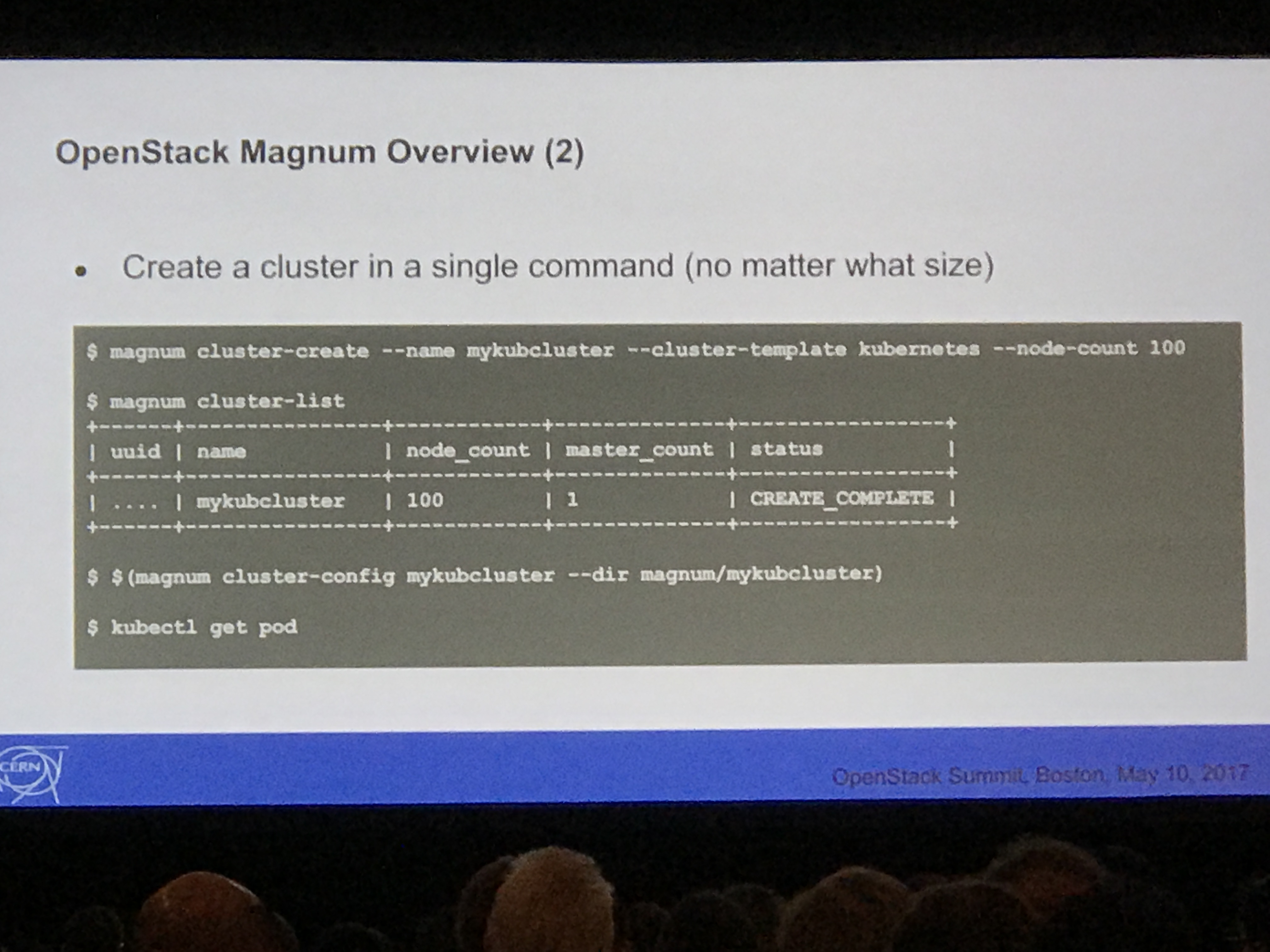
- Quickly creates new clusters with advanced features, like multi-master
Terminology:
- COE (Cluster Orchestration Engine)
- Magnum cluster (heat stack)
- COE sits atop
- Cluster template
- Resource in API
- Similar to heat template, but more abstract, shareable, and reusable
- Native client
- Magnum deploys COE
- You use 'native client' to manage, i.e. kubectl for k8s
- Magnum manages some TLS for COE
Why containers?
- Isolation
- Performance
- Resource utilization
- Ease of use
- Microservices
- Reduced attack surface
Overview
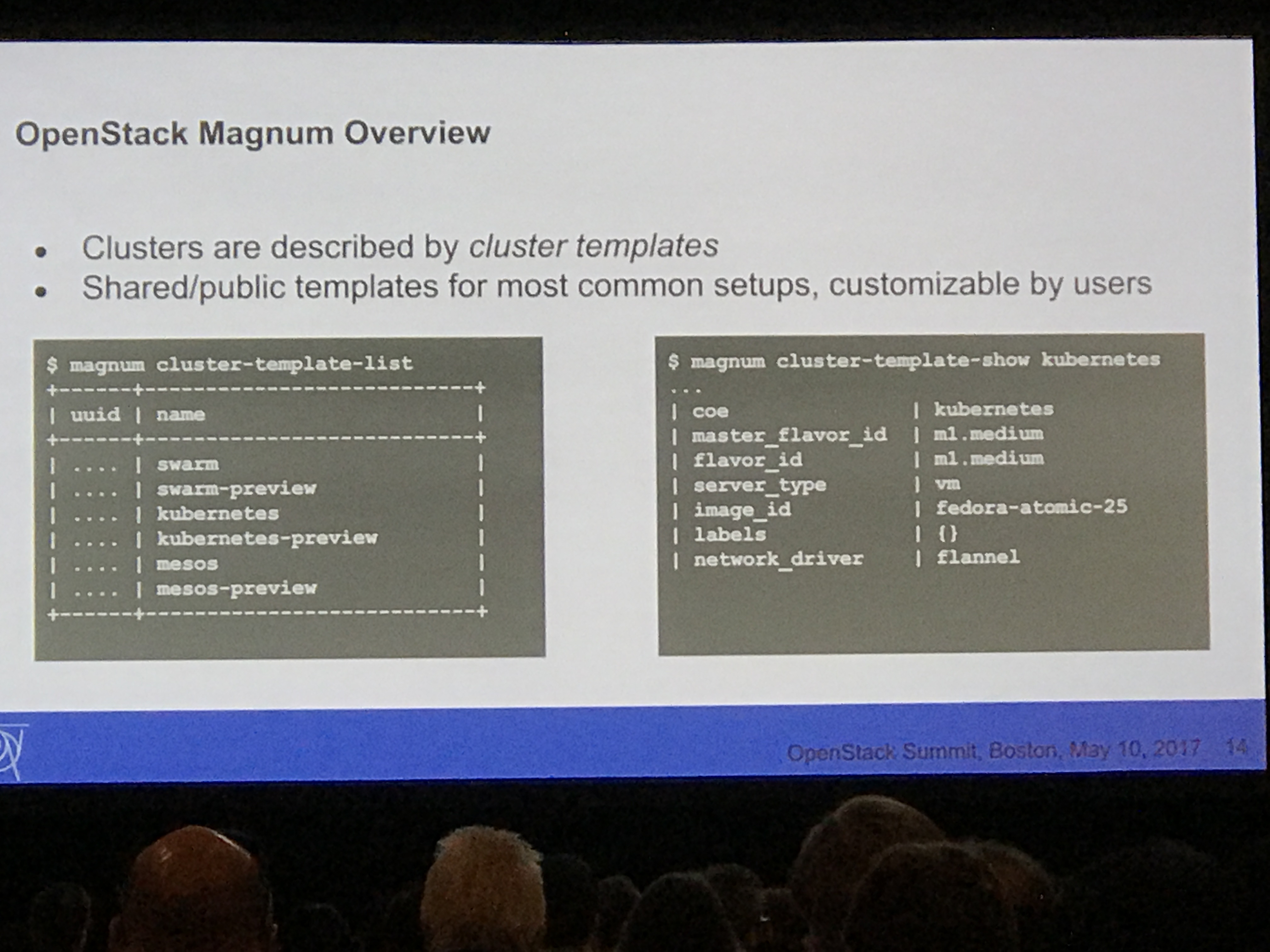
The template is the defaults, users can override, and customize. Clusters can be created in a single command.
Performance information included a test where CERN scaled to 2Million requests per second, and ran a deployment time test: http://superuser.openstack.org/articles/scaling-magnum-and-kubernetes-2-million-requests-per-second/

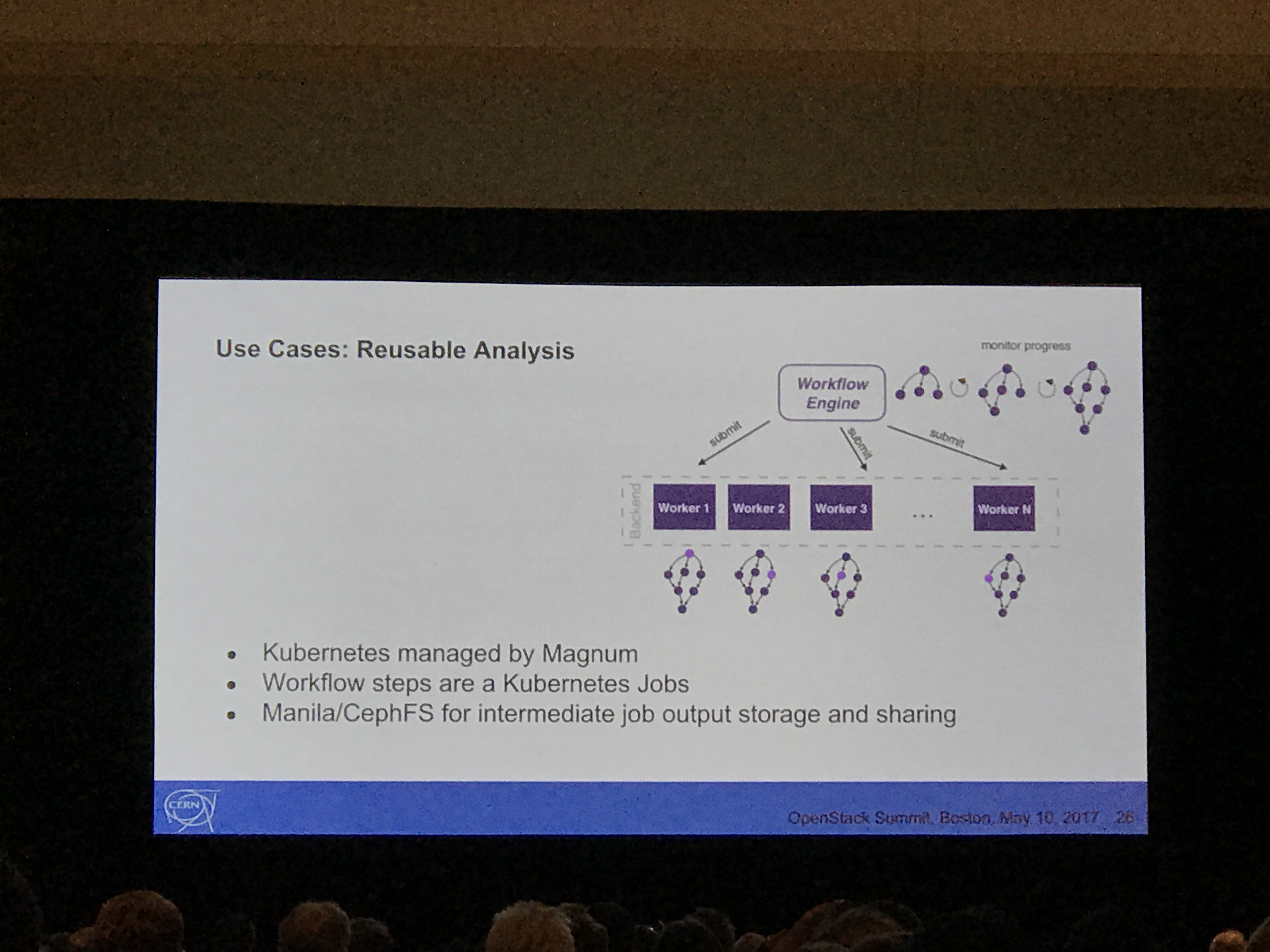
The closed with details on some integration work done at CERN, including CVMFS & EOS. They also detailed some of the use cases at CERN, which is primarily re-usable physics analysis. They added that they also run spark, deployed via Magnum for their interactive analysis.

Hybrid Messaging Solutions for Large Scale OpenStack Deployments
- Kenneth Giusti
- Mark Wagner
- https://www.openstack.org/videos/boston-2017/hybrid-messaging-solutions-for-large-scale-openstack-deployments
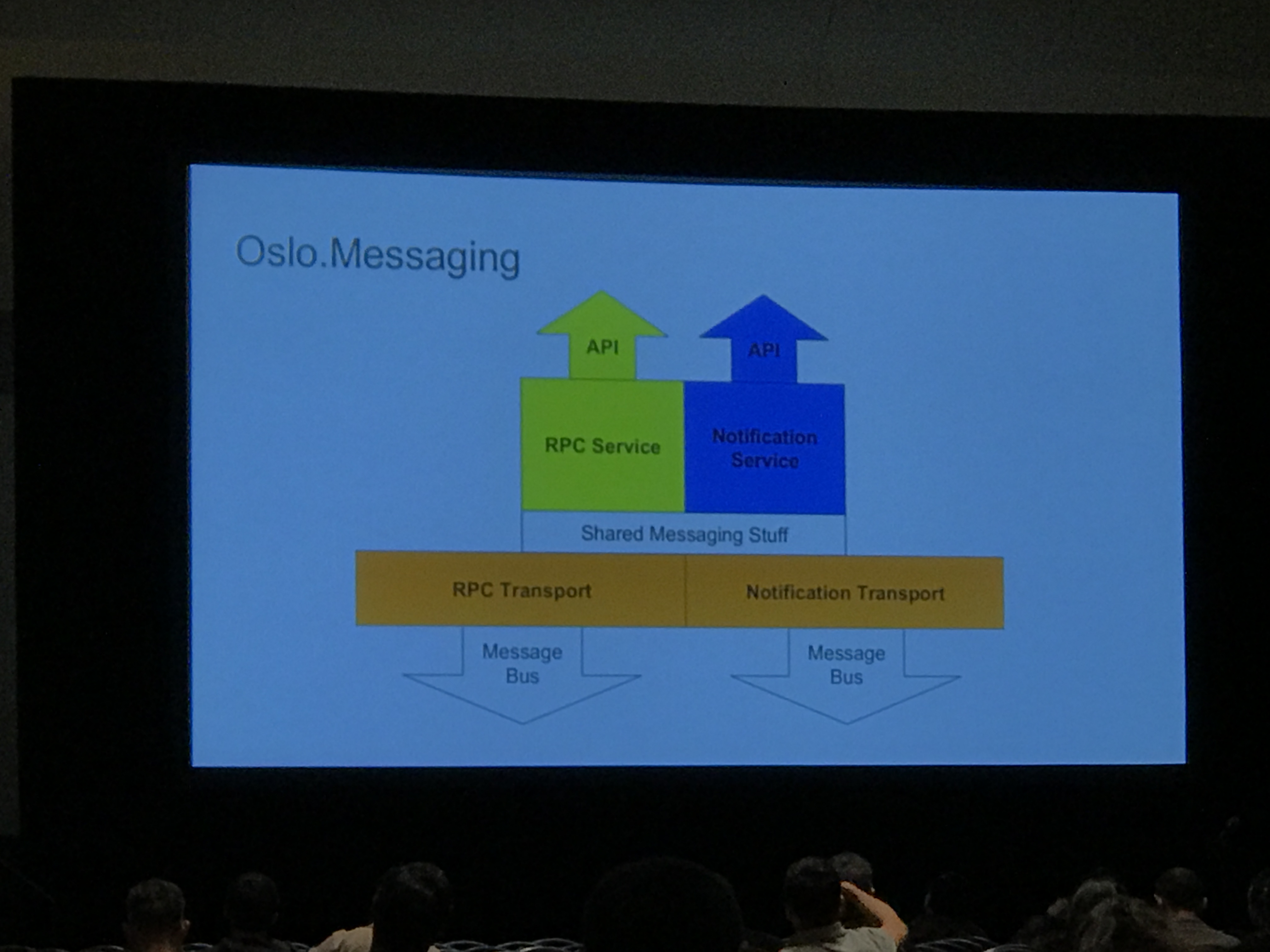
This session really dug into details on the oslo.messaging abstraction layer, including details about message types and messaging flow.
There are two types:
Notifications
Async from pub to sub(s)
Decoupled
Store and Forward
RPC
Synchronous
Bracketed
If sub not present, should fail
Not a queue
Details of the vanilla broker stack:
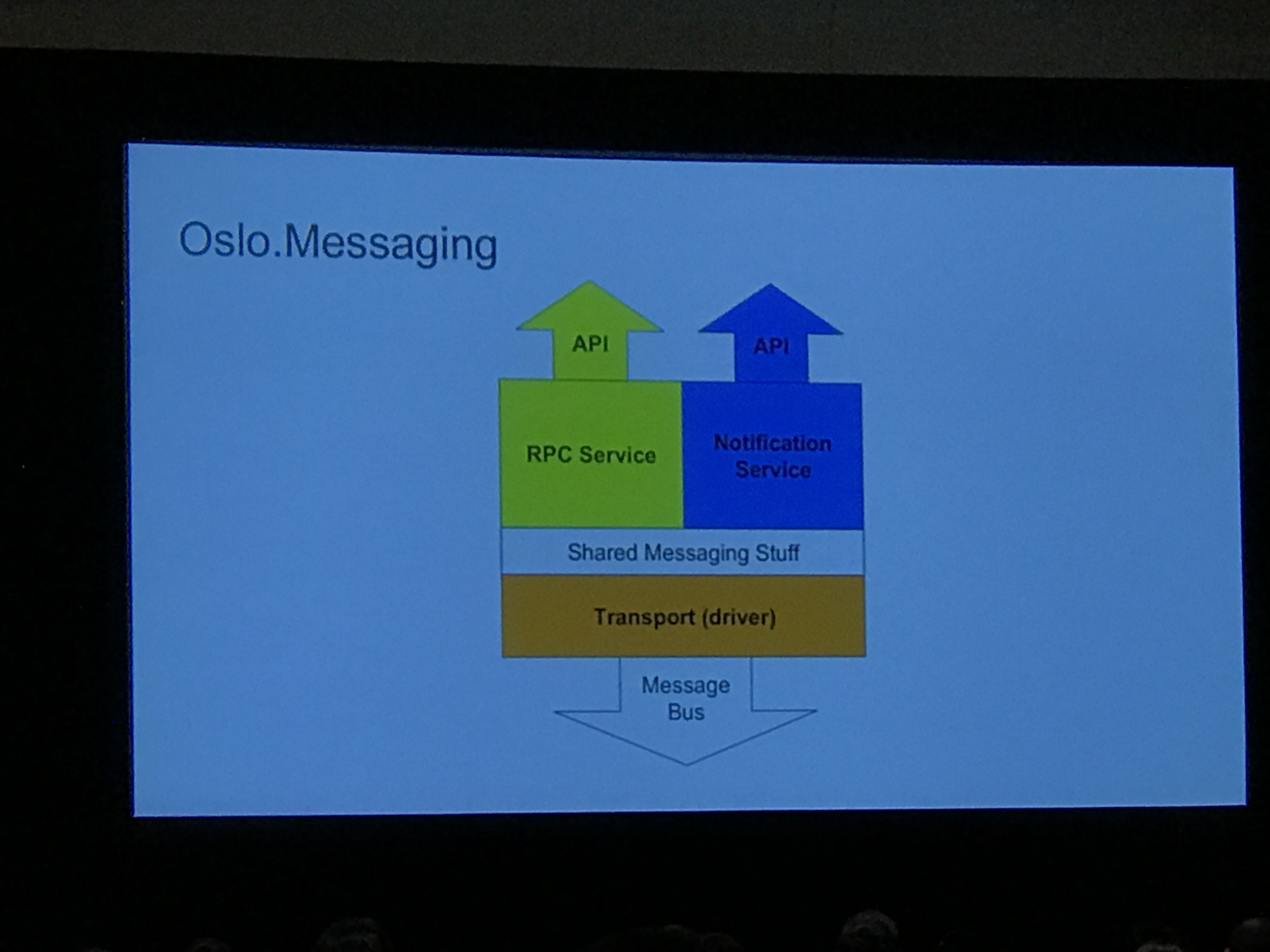
No client understanding of message type, and the result is not as efficient as it could be.
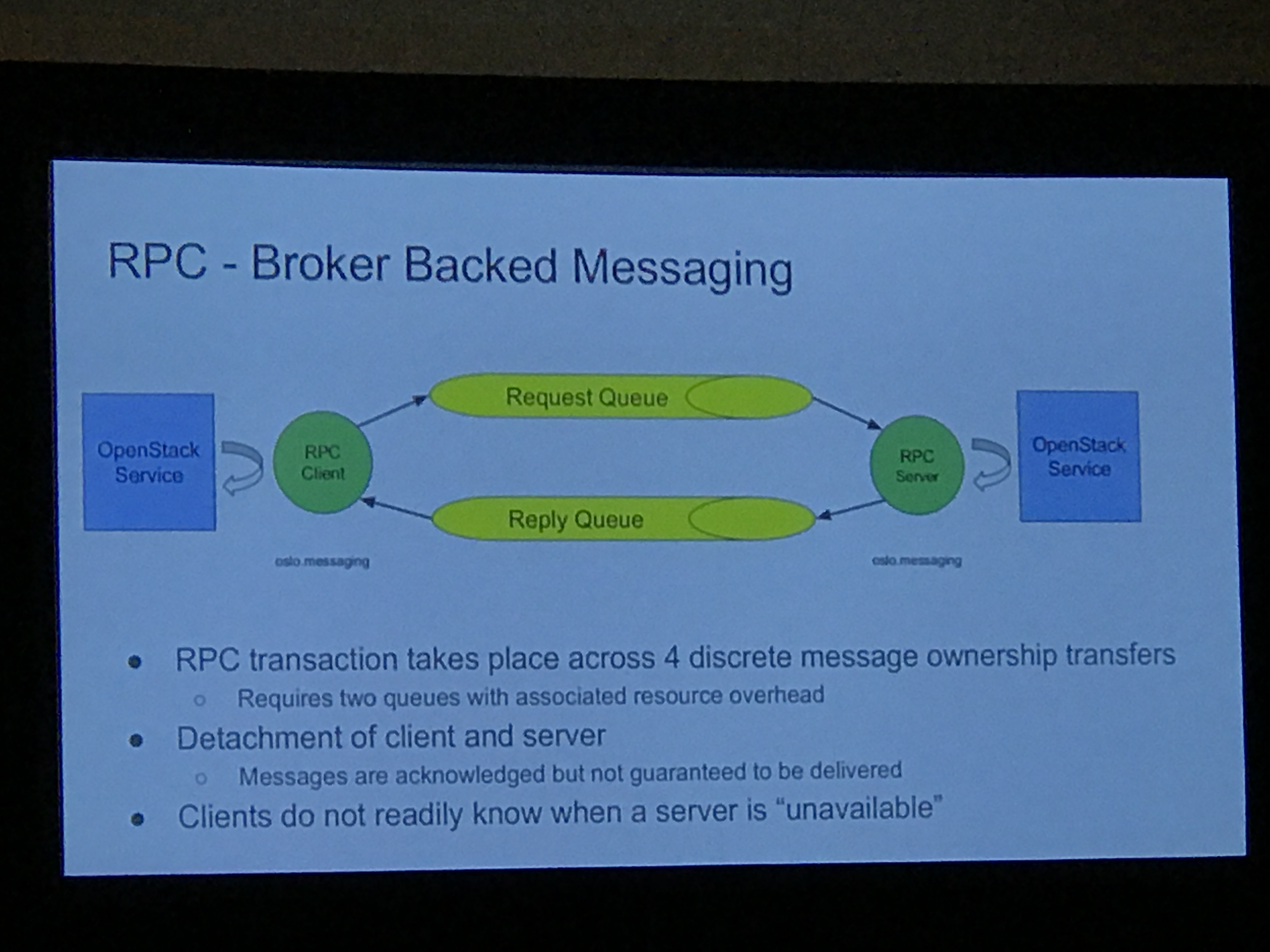
Hybrid broker stack:
The key difference here is that RPC is handled differently from notification; one way to configure this is "local mode" where RPC uses direct messaging:
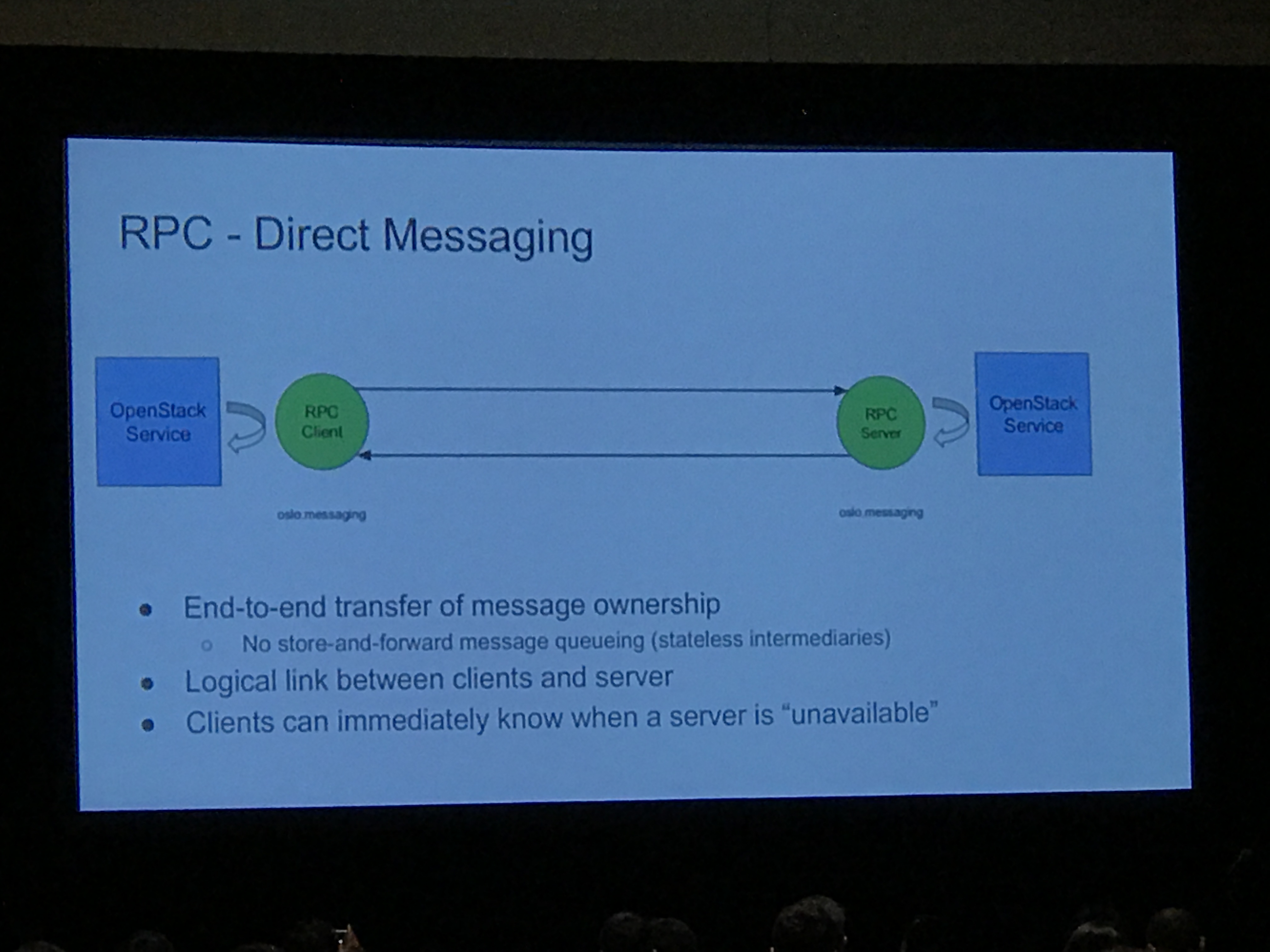
This makes the underlying connectivity more closely resemble the way the messaging is designed to work. The client knows if the server is unavailable. No stale messages can linger in a queue.
Some other details included AMQP 1.0 + distributed message router:
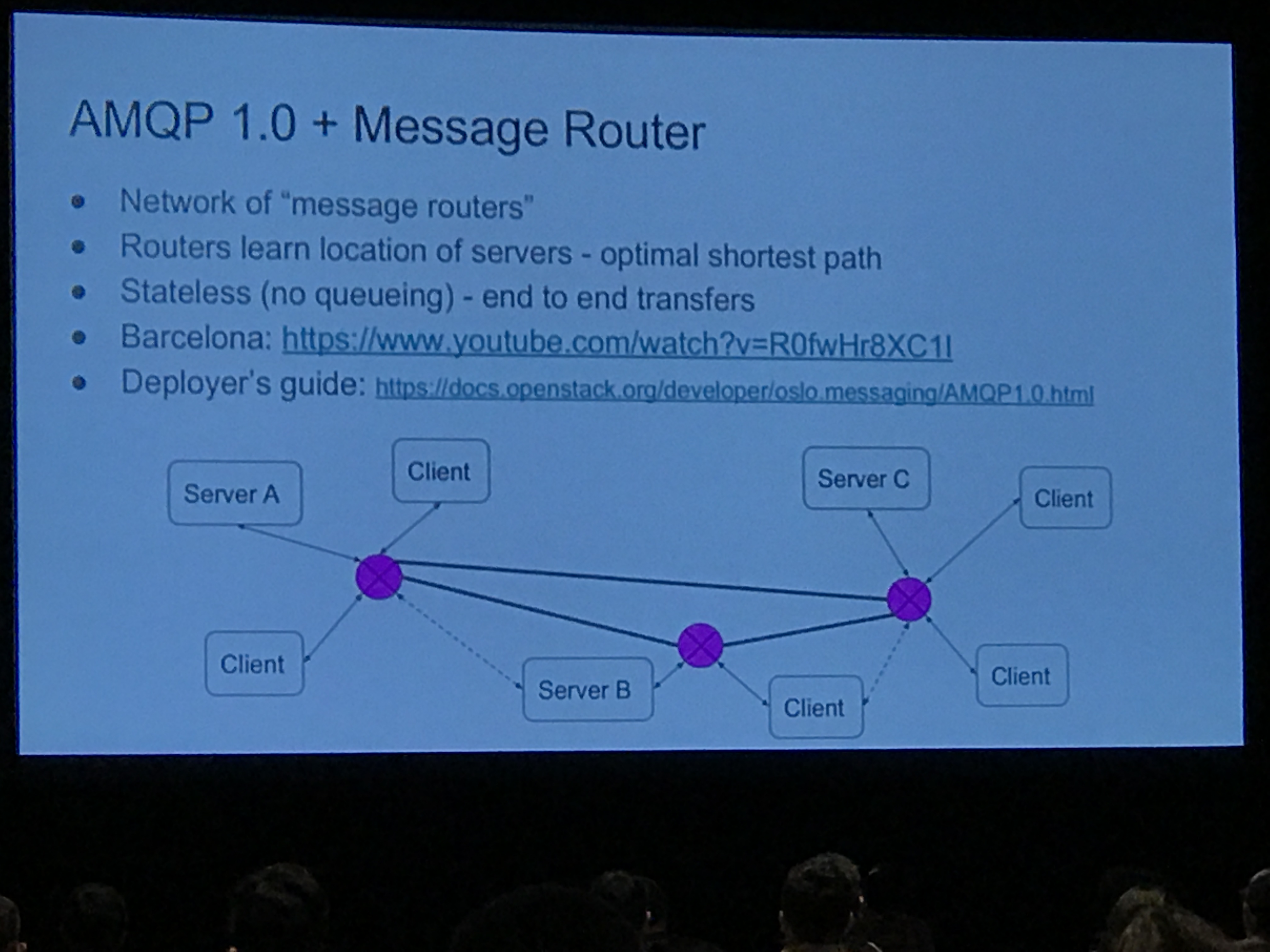
ZeroMQ Transport:

We also got some benchmarks and a matrix of drivers, backends and patterns supported, which included Kafka for notifications only. benchmarks were run with the olso.messaging tool, which is an artificial load tool, that Ken dubbed the "will it blend?" tool. It does not replicate an OpenStack load, but is designed to crush a message queue. Tests were based on single nodes, with no HA and no tuning, and the only variations were brokers/transports and persistent queues.

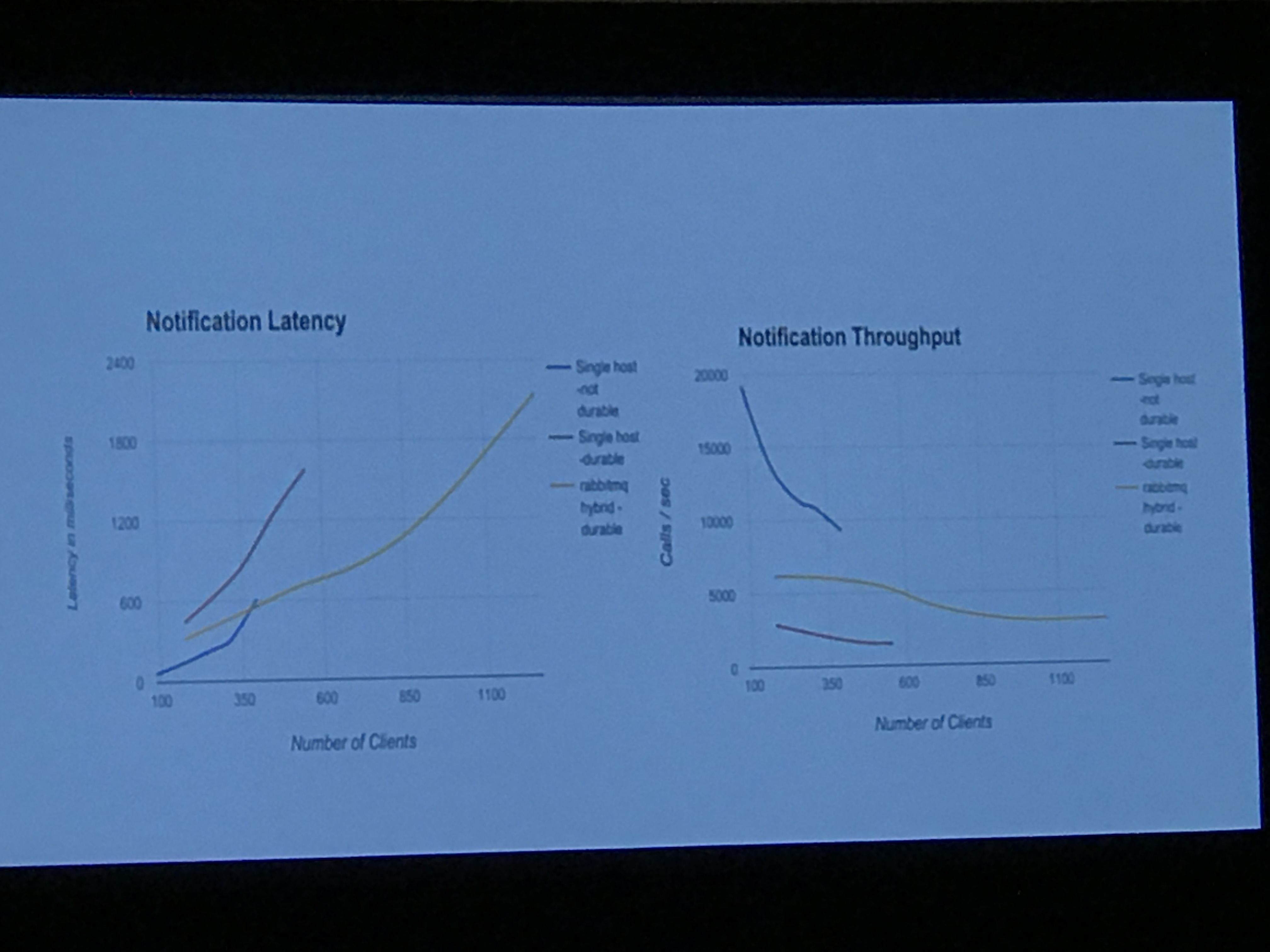
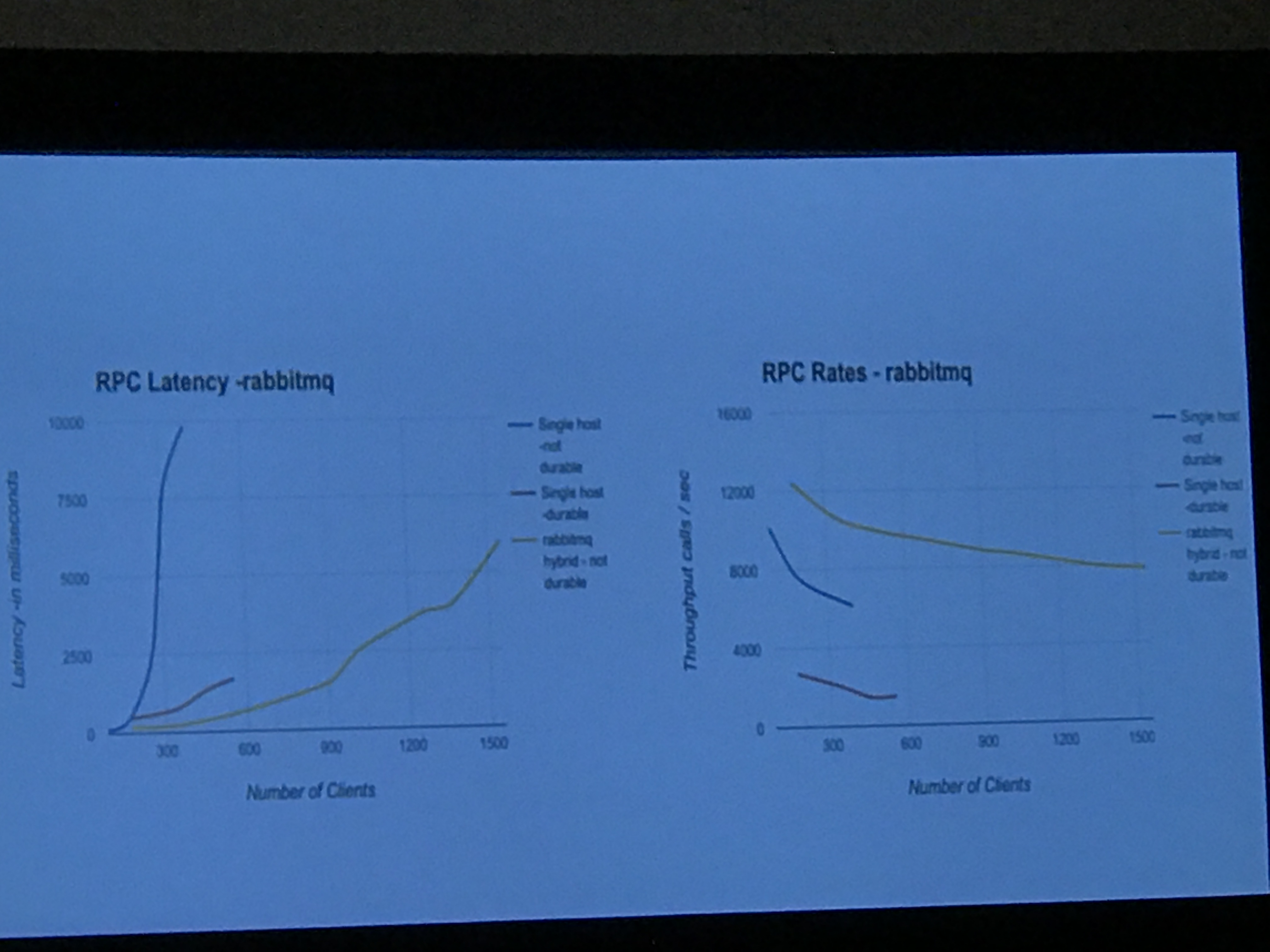
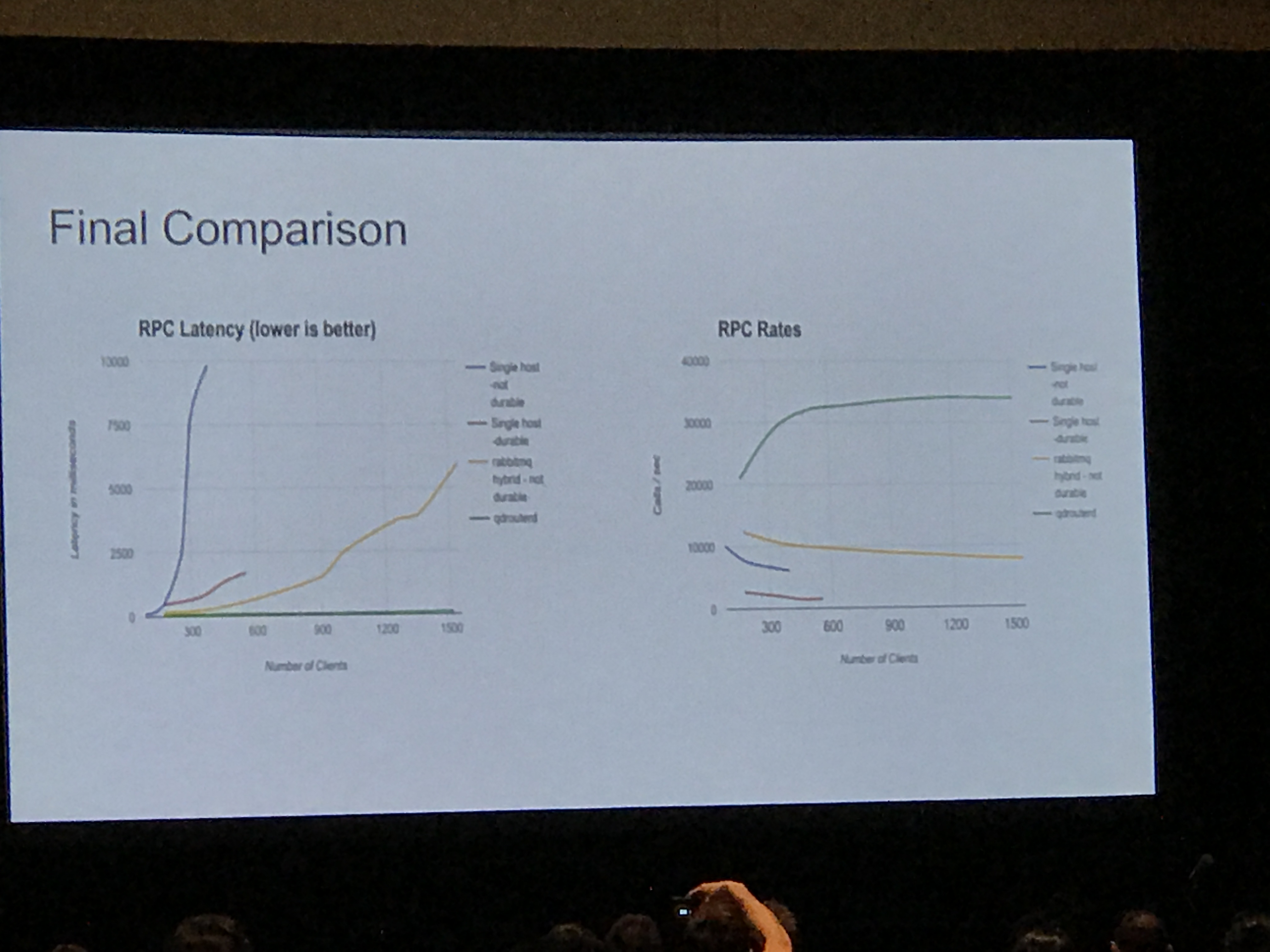
This was an excellent talk and was one of my favorites.
Scaling to 100 Nodes and Beyond
- Isaac Gonzalez
- Ianeta Hutchinson
- https://www.openstack.org/summit/boston-2017/summit-schedule/events/18334/scaling-to-100-nodes-and-beyond
I was excited about this session, but the presenters did not show up after 15-20 minutes, so I left. That was a disappointment.
